UK SMS SMPP
Character sets and encodings
What character sets do you use?
Almost all mobile handsets support two character sets for SMS messages, the GSM 03.38 character set and Unicode UCS-2 (with code points appropriate to the locale).
In order to cover the GSM 03.38 character set, you can submit messages directly in GSM 03.38 (the GSM character set) or in Modified Latin-9.
What is the different between UCS-2 and UTF-16?
UCS-2 and UTF-16 are virtually identical, but UCS-2 characters will always take exactly 16 bits. It is safe to increment and decrement by 16 bits for each character when parsing a message in your code
Character sets
These tables describe the GSM and Modified Latin-9 character sets.
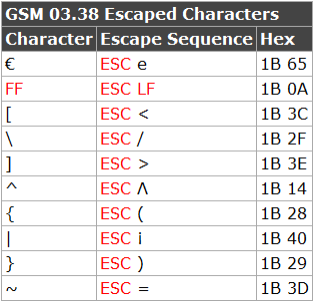
GSM character set
See also the Wikipedia article for more information: http://en.wikipedia.org/wiki/GSM_03.38.

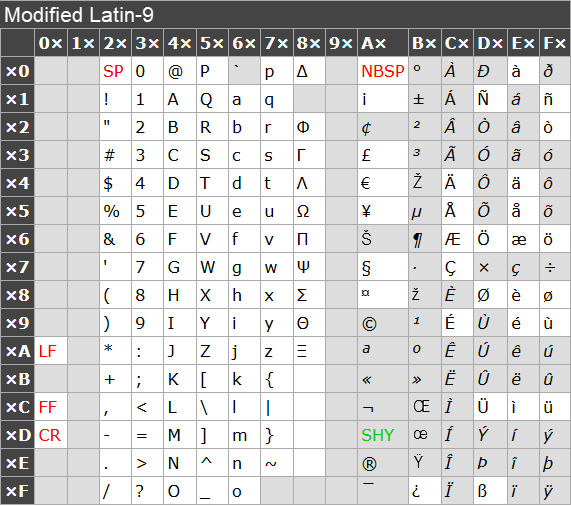
Modified Latin-9 character set
This character set is based on ISO-8859-15 (Latin-9). However, in order to fully cover the GSM character set and also has different characters at 0xA8, 0xA4, 0xA6, 0xB4, 0xB8, 0xBC, 0xBD, 0xBE. The characters not present in the GSM character set are shown on a grey background in the table below.
The acronyms in the table are:
- LF — line feed
- FF — form feed
- CR — carriage return
- SP — space
- NBSP — non-breaking space
- SHY — soft hyphen
See this Wikipedia article for more information about the Modified Latin-9 character set: https://en.wikipedia.org/wiki/ISO/IEC_8859-15.